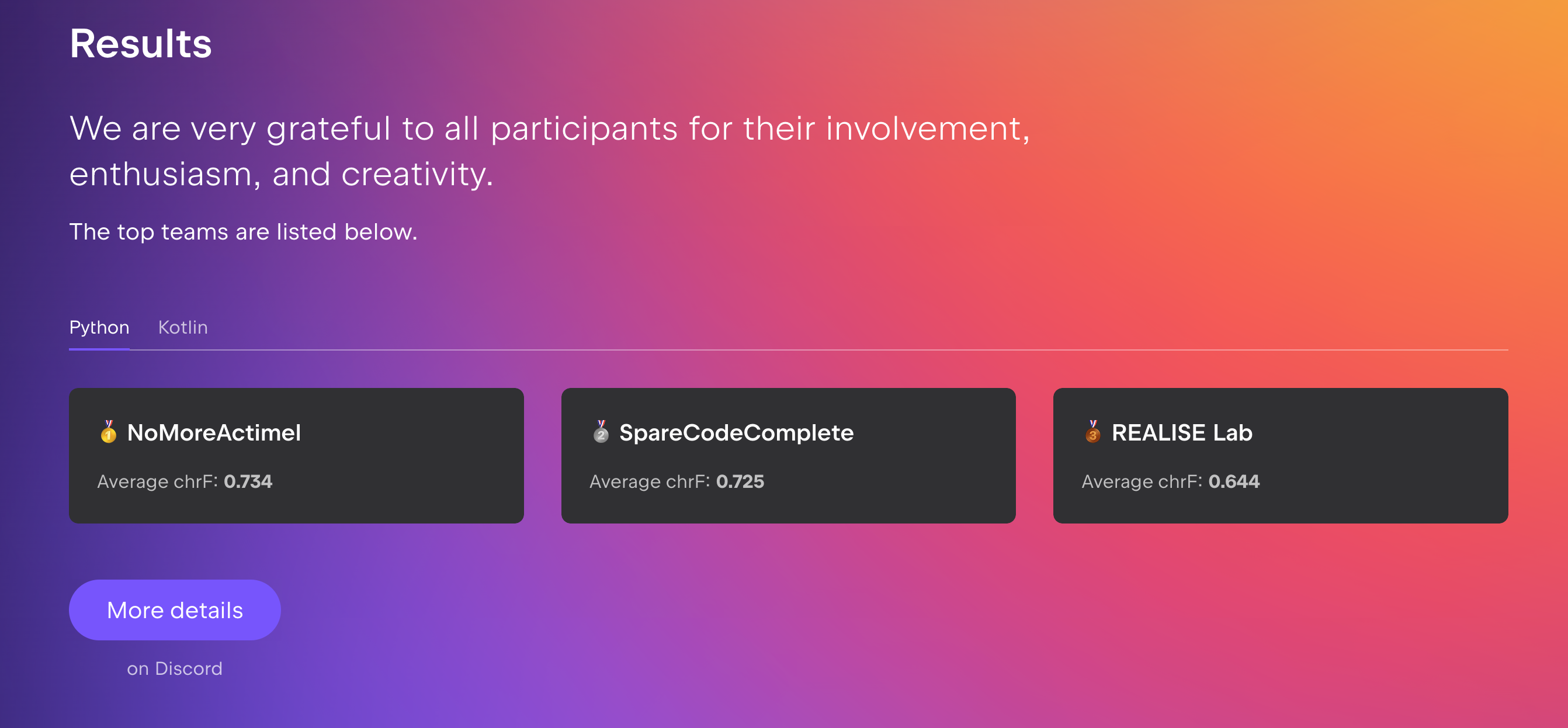
Our paper "Towards Supporting Open Source Library Maintainers with Community-Based Analytics" accepted at ICSE 2026! 🎉
How can OSS maintainers better understand the communities that depend on their work? While thousands of projects build on top of open libraries, maintainers often have limited visibility into how their code is actually being used. This gap matters: testing practices may overlook the very parts of the library most critical to dependents.
We introduce analytics that surface which features are most used by dependent projects and how well those features are tested.
Our analysis finds that not all community-used APIs are fully reflected in maintainers’ test suites, pointing to gaps that could inform more targeted maintenence strategies. We observe that while maintainers provide extensive tests, unit test suites does not always extend to every API most relied upon by dependents.”
Interested? You can find a pre-print of our paper here.