Congratulations to Bilel for being selected to attend MenaML AI school in King Abdullah University of Science and Technology (KAUST) in January 2026. Bilel will present an AI-related work produced by REALISE LAB.

Congratulations to Bilel for being selected to attend MenaML AI school in King Abdullah University of Science and Technology (KAUST) in January 2026. Bilel will present an AI-related work produced by REALISE LAB.
Huge congratulations to Rachna Raj for receiving the Google 2025 North America PhD Fellowship in Software Engineering and Programming Languages!
Rachna's PhD project focuses on developing techniques to support open-source software maintainers. It is amazing to see Google's and Google Research recognition and support for such a significant problem.
Interested in her work? Please take a look at our latest #ICSE paper, "Towards Supporting Open Source Library Maintainers with Community-Based Analytics." She will present this work in Rio de Janeiro in April 2026.
![]()
How can OSS maintainers better understand the communities that depend on their work? While thousands of projects build on top of open libraries, maintainers often have limited visibility into how their code is actually being used. This gap matters: testing practices may overlook the very parts of the library most critical to dependents.
We introduce analytics that surface which features are most used by dependent projects and how well those features are tested.
Our analysis finds that not all community-used APIs are fully reflected in maintainers’ test suites, pointing to gaps that could inform more targeted maintenence strategies. We observe that while maintainers provide extensive tests, unit test suites does not always extend to every API most relied upon by dependents.”
Interested? You can find a pre-print of our paper here.
We are happy to announce that our paper "Beyond More Context: How Granularity and Order Drive Code Completion Quality" was accepted in the Context Competition Challenge Workshop, colocated with ASE 2025. This work was authored by Uswat Yusuf during her internship at RealiseLab last summer.
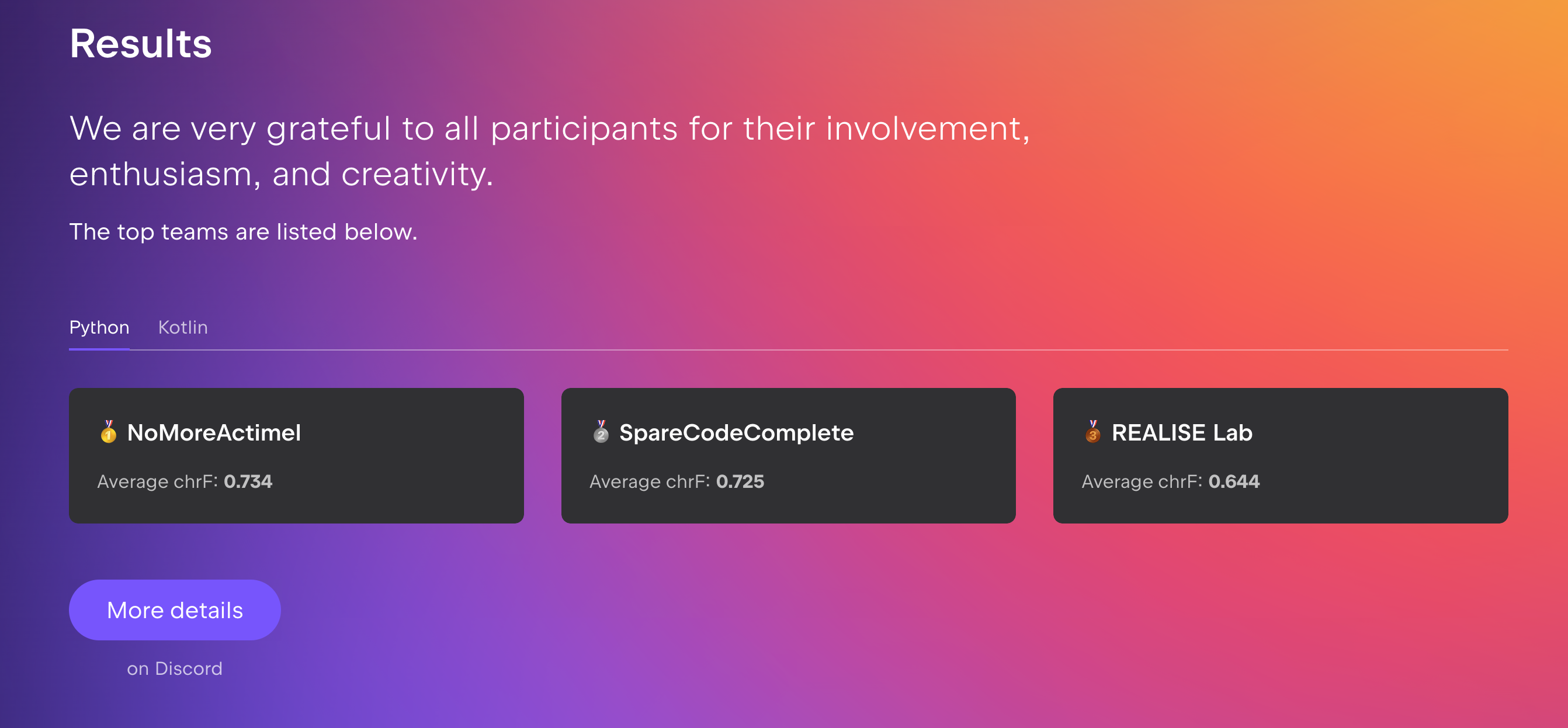
The competition challenged participants to develop strategies for gathering code context to maximize the performance of code completion models, based on a baseline provided by JetBrains. Our team achieved third place in the competition! We experimented with file chunking and chunk ordering on both Python and Kotlin source files, and found that chunk-level retrieval outperforms file-level retrieval.
As winter is approaching by the hour, Montréalers, including ourselves, are making most out of summertime while possible. Therefore, for a brief summmer afternoon, we turn off the Overleaf and Google colab tabs (but not our laptops because the 'experiment is running', it is always the case) and head out for a sunshine hunt hike, and since Concordia is in downtown, there is no better option than to do the hike in Mont Royal, the iconic landmark of the island. This hike became our yearly ritual. We started the hike with a convinient lunch of Kebab sandwiches in the Chalet across Beaver lake. Before proceeding to the summit, we had to get that Beaver lake picture and it couldn't look any better.
 We continued the hike towards the summit to take the iconic view of the Montréal skyline. After too much effort to claim some space among the touristic crowds, we were able to capture the picture.
We continued the hike towards the summit to take the iconic view of the Montréal skyline. After too much effort to claim some space among the touristic crowds, we were able to capture the picture.
 We wraped the hike with a Freesbe game under the shadows of the mountain trees.
This hike was the opportunity to show our interns, especially our (relatively) new international Mitacs interns, how beautiful Montréal is. Also, at the end of the hike, we said our farewell to our beloved Haya and wished to her a safe trip back to Palestine.
We wraped the hike with a Freesbe game under the shadows of the mountain trees.
This hike was the opportunity to show our interns, especially our (relatively) new international Mitacs interns, how beautiful Montréal is. Also, at the end of the hike, we said our farewell to our beloved Haya and wished to her a safe trip back to Palestine.
What are the trade-offs of heavily relying on Free and Open-Source (FOSS) components to develop your own software system? How much faster are you able to ship your code to production versus what security risks you may expose your system to?
Interested? You can find a pre-print of our paper here.
Performance regressions in software systems can lead to significant financial losses and degraded user satisfaction, making their early detection and mitigation critical.
One of the major issues encountered in both the academic and industrial landscapes is access to data from the industry, and this issue prevales in performance engineering as such datasets contain information about a company's internal systems. To address this gap, we introduce a unique dataset to support various research studies in performance engineering, anomaly detection, and machine learning.
This paper introduces a unique dataset of performance measurements and alerts from Mozilla, aimed at advancing research in performance engineering and anomaly detection.
Collected from Mozilla Firefox’s testing systems, this dataset contains:
How does smaller and open-source Large Language Models compare to ChatGPT in refining code? Our study dives into code reviews, a cornerstone of modern software development. While code reviews are indispensable for ensuring quality and transferring knowledge, they can also become bottlenecks in large-scale projects.
Great news! Concordia has decided to fund the second edition of REANIMATE, our summer school on Retro Gaming History, Critic, and Development. This funds are part of the Aid to Research Related Events, Exhibition, Publication and Dissemination Activities (ARRE) Program.
The first edition of Reanimate'24 was organized by Prof. Yann Gael and team, and had a rich program, with 11 speakers from academia and industry, who shared their knowledge to participants of the event. The event included 5 full days of activities with talks, game jams, workshops, and it was a success. I am thrilled to join the organization for the second event, and glad that Concordia will be able to host the summer school again in 2025.
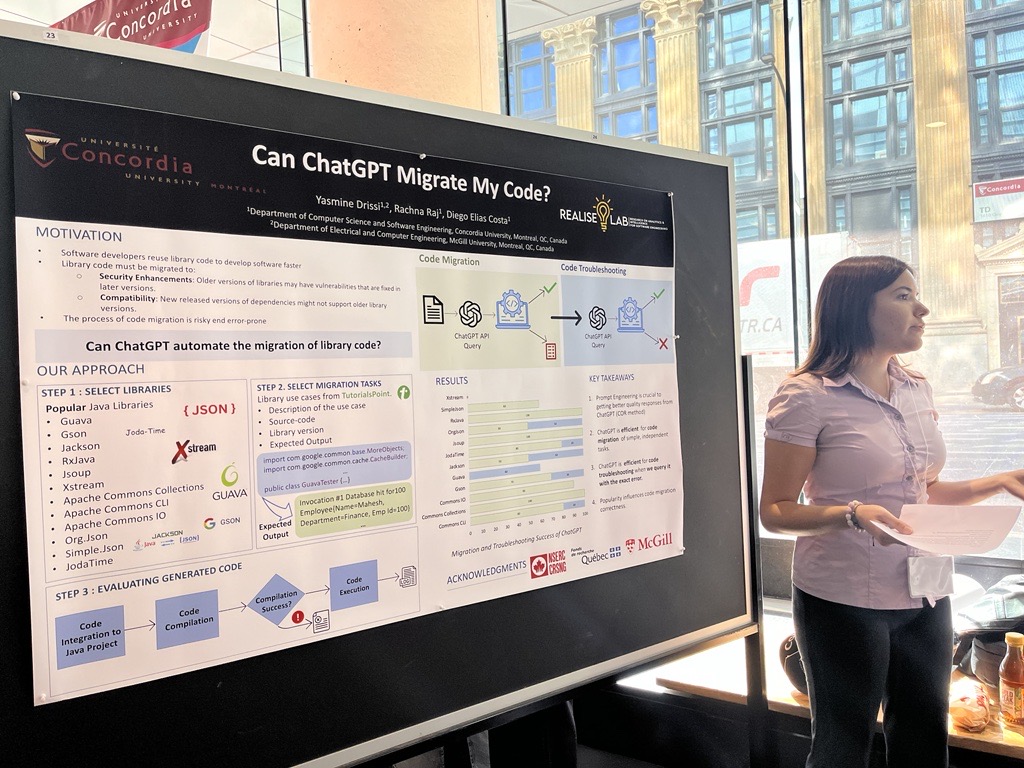 Yasmine presented her summer internship work at the Undergraduate Research Showcase at Concordia University. Her work entitled "Can ChatGPT Migrate My Code" explores the idea of using ChatGPT for migrating code that uses third-party libraries. The experiment consisted in prompting ChatGPT to migrate the code of one library version to another, and evaluating whether the generated code was correct. And the results were promising, with ChatGPT achieving a much higher degree of success than we originally anticipated.
Yasmine presented her summer internship work at the Undergraduate Research Showcase at Concordia University. Her work entitled "Can ChatGPT Migrate My Code" explores the idea of using ChatGPT for migrating code that uses third-party libraries. The experiment consisted in prompting ChatGPT to migrate the code of one library version to another, and evaluating whether the generated code was correct. And the results were promising, with ChatGPT achieving a much higher degree of success than we originally anticipated.
 The poster presentation was a great success, way to go Yasmine! If you are interested in the details of this project, keep an eye out as we are preparing a paper submission soon.
The poster presentation was a great success, way to go Yasmine! If you are interested in the details of this project, keep an eye out as we are preparing a paper submission soon.